Are OpenTelemetry Collector Exporters Called Sequentially or in Parallel?
You have configured multiple exporters in a single OpenTelemetry Collector pipeline: one for your production observability backend, and perhaps another for a local debugging tool or a data archive. It is tempting to assume the Collector broadcasts telemetry to all of them simultaneously.
The reality is more nuanced. The Collector calls exporters sequentially, in the order they appear in the pipeline. But the sending queue normally hides that from you, so in practice it behaves as if it were parallel. The interesting question is what happens when that illusion is put under pressure, and the answer changed at some point, which is why a lot of the advice you will find online is now wrong.
The fan-out mechanism
The component responsible for delivering data to multiple exporters within a single pipeline is the fan-out consumer. It iterates over the configured exporters in the order they appear in your configuration.
Consider this pipeline:
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
exporters:
otlp/prod:
endpoint: 'api.vendor.com:4317'
otlp/archive:
endpoint: 'archive.internal:4317'
service:
pipelines:
traces:
receivers: [otlp]
exporters: [otlp/prod, otlp/archive]
When the Collector processes a batch of traces, the fan-out consumer performs a simple loop: it calls ConsumeTraces on otlp/prod, waits for that call to return, then calls ConsumeTraces on otlp/archive. The hand-off is inherently sequential.
There is one detail worth knowing for correctness: the fan-out consumer accumulates errors rather than aborting on the first one. If an exporter returns an error, the loop records it and still proceeds to the next exporter. A hard failure in otlp/prod does not, by itself, prevent otlp/archive from receiving its copy.
The role of queues
If the execution is sequential, does otlp/archive have to wait for otlp/prod to complete a network request across the internet?
No. The OTLP exporter (like most core exporters) is built on the exporterhelper package, which enables a sending queue by default. That queue changes what ConsumeTraces actually does.
With the queue enabled, ConsumeTraces does not send anything over the network. It enqueues the data into an in-memory buffer and returns almost immediately. Each exporter has its own pool of background consumers, ten by default, that drain its queue and handle network transmission independently.
So the real flow is:
- The fan-out consumer enqueues the batch on
otlp/prod's queue and returns immediately. - It enqueues the batch on
otlp/archive's queue and returns immediately. - Background consumers for each exporter pick up the data and transmit it over the network in parallel.
On the happy path, the system behaves as if it were parallel, even though the initial hand-off is strictly sequential. Two exporters with full queues drain concurrently; one slow backend does not make the other wait for its network round-trip.
What happens when a queue fills up
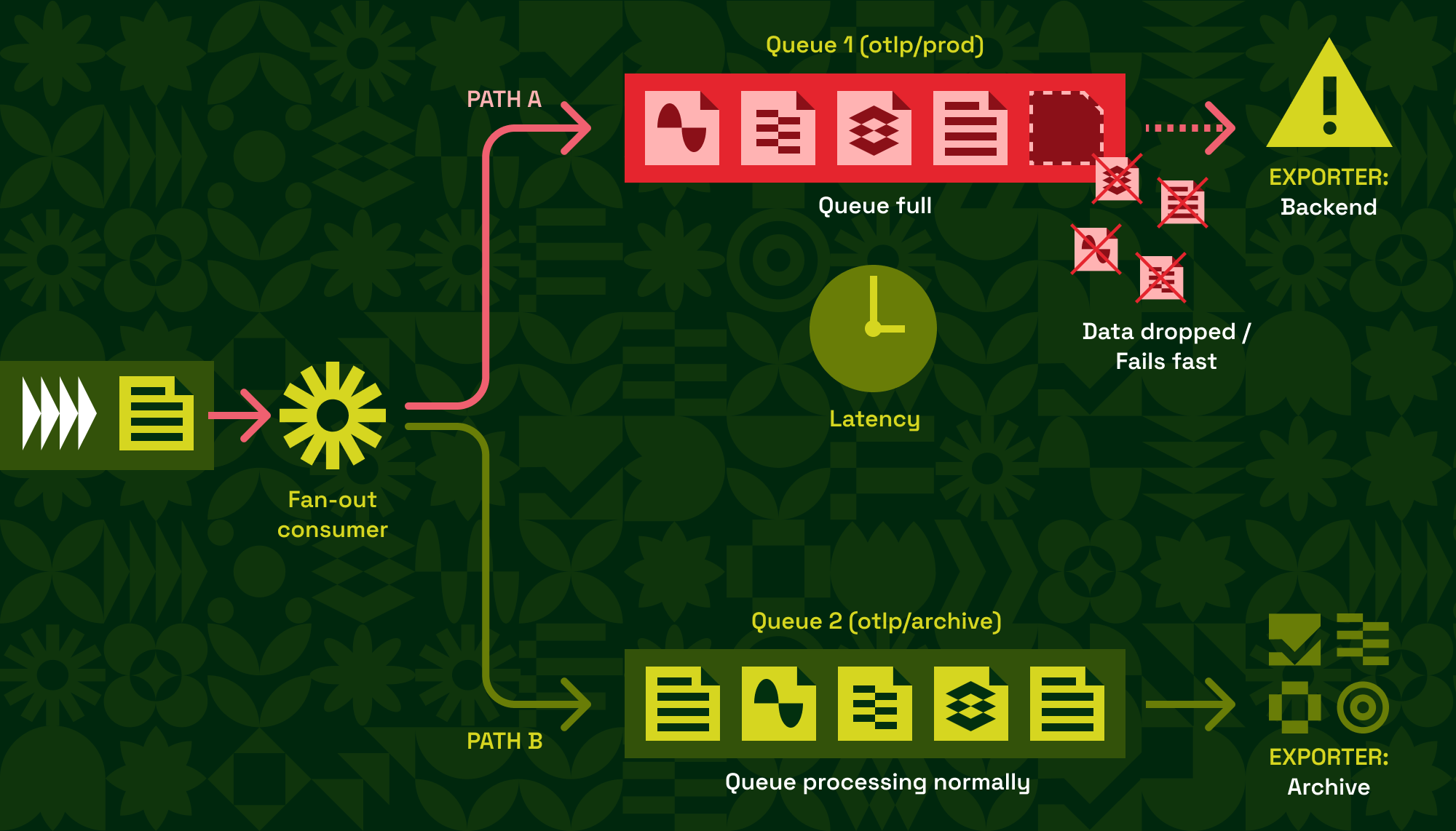
The decoupling holds only while there is room in the queue. The important question, and the one that trips people up, is what the Collector does when a queue is full.
This is governed by a single setting, sending_queue.block_on_overflow, and its default is false:
exporters:
otlp:
sending_queue:
enabled: true
queue_size: 1000 # default; measured in requests
block_on_overflow: false # default
With block_on_overflow: false, enqueuing onto a full queue returns a retryable error immediately instead of waiting. It does not block the caller. So if otlp/prod is unhealthy and its queue is saturated, here is what happens on the next batch:
- The push to
otlp/prodfails fast with a "queue is full" error. The fan-out consumer records it. - The loop moves on and enqueues the batch on
otlp/archive, which is healthy and has room. otlp/archivekeeps receiving data normally.
In other words, by default, latency is isolated. A slow or stalled backend cannot hold the fan-out loop hostage, because the hand-off to its queue never blocks; it just fails fast for the data it cannot accept.
There is a cost, of course: the data that could not be enqueued for otlp/prod is rejected back up the pipeline. Note that this is not the same as retry_on_failure, which only applies to network send failures after a batch has been dequeued. An enqueue failure is returned to whoever called the pipeline. For the OTLP receiver, that means a gRPC error goes back to the upstream client, which can decide to retry. The default trades durability for isolation: when a destination is overwhelmed, you shed its load rather than letting it stall everything else.
Opting into backpressure
If you would rather not drop data, you can flip the behavior:
exporters:
otlp:
sending_queue:
enabled: true
block_on_overflow: true
With block_on_overflow: true, enqueuing onto a full queue blocks until space frees up. This is genuine backpressure, and it is exactly the head-of-line-blocking scenario people warn about, except now it is something you opted into:
- The push to the full
otlp/prodqueue blocks, waiting for space. - The fan-out consumer is stuck on the first exporter.
- The call to
otlp/archiveis delayed for as long asotlp/prodstays saturated.
Worse, that backpressure propagates upstream. A blocked enqueue means the receiver cannot return, so it stops reading from the network, which stalls every exporter in the pipeline and every producer feeding it. With this setting, a single slow vendor really can degrade delivery to your local archive.
This is the right choice when losing data is unacceptable and you would rather slow everything down than drop anything. It is the wrong choice when you have a critical, healthy destination that must not be held hostage by a struggling one. The point is that it is now a deliberate decision, not a hidden default.
A note on why the old advice says the opposite
If you have read that "the Collector applies backpressure by default" or that "a full queue blocks the pipeline," that advice was not wrong when it was written. Earlier Collector releases used a bounded in-memory queue that blocked the caller when full: blocking was the default behavior, with no knob to turn it off short of disabling the queue entirely.
The queue implementation was later reworked (the queuebatch refactor in exporterhelper), and the default flipped to non-blocking, with block_on_overflow added as the explicit opt-in. The version number on the binary did not announce this in a way most readers noticed, so a lot of still-circulating guidance describes behavior that is no longer the default. When you read advice about Collector queue behavior, check which era it was written for, and better yet, check the behavior of the exact build you ship.
Recommendations
1. Keep sending queues enabled. They are on by default in the OTLP exporter, and they are what gives you the as-if-parallel behavior. Disabling the queue forces the fan-out consumer to wait for the actual network request, which guarantees that your slowest exporter dictates the throughput of the entire pipeline.
2. Decide your overflow policy on purpose. The default (block_on_overflow: false) isolates latency by shedding load from an overwhelmed destination. Setting block_on_overflow: true protects against data loss but couples the fate of every exporter (and the receiver) to your slowest backend. Pick the one that matches what you are optimizing for; do not inherit it by accident.
3. Monitor your queues. Watch otelcol_exporter_queue_size against otelcol_exporter_queue_capacity. A queue that constantly hovers near capacity is a bottleneck. Pair it with otelcol_exporter_enqueue_failed_spans (and the metric/log equivalents): under the default policy, that is where shed data shows up, silently, unless you are looking.
4. For true isolation, use separate Collector instances. Splitting destinations into separate pipelines within one Collector helps, but remember the receiver caveat: if you have set block_on_overflow: true on any pipeline, a stalled enqueue there can stop the shared receiver from reading the network, which affects every pipeline. Hard isolation between a critical destination and a flaky one is most reliably achieved with separate Collector processes.
Summary
The OpenTelemetry Collector calls exporters sequentially, and the sending_queue is what turns that sequential hand-off into effectively parallel delivery. By default, a full queue fails fast (block_on_overflow: false), so one slow backend isolates its own latency at the cost of shedding its own data. Backpressure and head-of-line blocking are real, but they are the opt-in behavior (block_on_overflow: true), not the default they once were. Keep your queues enabled, choose your overflow policy deliberately, and monitor queue size and enqueue failures so you know which trade-off you are actually living with.